Guidelines and best practices
Things to keep in mind when implementing a Mastodon app.
Last modified
Edit this page
Login
The user must be able to login to any Mastodon server from the app. This means you must ask for the server’s domain and use the app registrations API to dynamically obtain OAuth2 credentials.
Usernames
Decentralization must be transparent to the user. It should be possible to see that a given user is from another server, for example, by displaying their acct somewhere. Note that acct is equal to username for local users, and equal to username@domain for remote users.
Handling and sorting IDs
Vanilla Mastodon entity IDs are generated as integers and cast to string. However, this does not mean that IDs are integers, nor should they be cast to integer! Doing so can lead to broken client apps due to integer overflow, so always treat IDs as strings.
With that said, because IDs are string representations of numbers, they can still be sorted chronologically very easily by doing the following:
- Sort by size. Newer statuses will have longer IDs.
- Sort lexically. Newer statuses will have at least one digit that is higher when compared positionally.
Paginating through API responses
Many API methods allow you to paginate for more information, using parameters such as limit, max_id, min_id, and since_id. However, some of these API methods operate on entity IDs that are not publicly exposed in the API response, and are only known to the backend and the database. (This is usually the case for entities that reference other entities, such as Follow entities which reference Accounts, or Favourite entities which reference Statuses, etc.)
To get around this, Mastodon may return links to a “prev” and “next” page. These links are made available via the HTTP Link header on the response. Consider the following fictitious API call:
GET https://mastodon.example/api/v1/endpoint HTTP/1.1
Authorization: Bearer token
Link: <https://mastodon.example/api/v1/endpoint?max_id=7163058>; rel="next", <https://mastodon.example/api/v1/endpoint?since_id=7275607>; rel="prev"
[
{
// some Entity
},
// more Entities in an Array
]
In this case, you may retrieve the Link header and parse it for links to the older or newer page. Keep in mind the following rules:
- The links will be returned all via one
Linkheader, separated by a comma and a space (,) - Each link consists of a URL and a link relation, separated by a semicolon and a space (
;) - The URL will be surrounded by angle brackets (
<>), and the link relation will be surrounded by double quotes ("") and prefixed withrel=. - The value of the link relation will be either
prevornext.
Following the next link should show you older results. Following the prev link should show you newer results.
Formatting
Plain text is not available for content from remote servers, and plain text syntax rules may vary wildly between Mastodon and other fediverse applications. For certain attributes, such as the content of statuses, Mastodon provides sanitized HTML. See HTML Sanitization for more details. You may expect these tags to appear in the content:
<p><br><span><a>
Mentions, hashtags, and custom emoji
Mentions and hashtags are <a> tags. Custom emoji remain in their plain text shortcode form. To give those entities their semantic meaning and add special handling, such as opening a mentioned profile within your app instead of as a web page, metadata is included with the
Status, which can be matched to a particular tag.
Link shortening
Links in Mastodon are not shortened using URL shorteners, and the usage of URL shorteners is heavily discouraged. URLs in text always count for 23 characters, and are intended to be shortened visually. For that purpose, a link is marked up like this:
<a href="https://example.com/page/that/is/very/long">
<span class="invisible">https://</span>
<span class="ellipsis">example.com/page</span>
<span class="invisible">/that/is/very/long</span>
</a>
The spans with the invisible class can be hidden. The middle span is intended to remain visible. It may have no class if the URL is not very long; otherwise it will have an ellipsis class. No ellipsis (…) character is inserted in the markup; instead, you are expected to insert it yourself if you need it in your app.
Filters
Server-side filtering (v2, Mastodon 4.0 and above)
If a filter applies to a Status, a corresponding FilterResult will be included in the filtered attribute. Clients should check this attribute for any matches and use them to apply the intended filter action.
However, client implementations may still want to perform their own rule matching client-side, as this would allow retroactively apply filter changes without re-fetching posts from the server. When doing so, they should take care to not ignore filtered entries for which there are other attributes than keyword_matches, so as to handle extensions of the filtering system (e.g. status_matches).
Matched filters need to be filtered based on context (home, notifications, public, thread or profile) and expiration date.
When at least one active matched filter has hide for filter_action, the post should not be shown at all. Otherwise, if at least one active matched filter has warn for filter_action, the post should be hidden with a warning, and the user should be able to reveal the post after being informed of which filters matched (identified by title rather than the exact matched keywords).
For extension purposes, unknown values for filter_action should be treated as warn.
Client-side filtering (v1, prior to Mastodon 4.0)
Clients must do their own text filtering based on filters returned from the API. The server will apply irreversible filters for home and notifications contexts, but anything else is still up to the client to filter! If a status is somehow not removed by an irreversible filter, the client should still filter it.
Expired filters are not deleted by the server. They should no longer be applied, but they are still stored by the server, as users may update the expiry time to re-enable the filter. It is up to users to delete those filters eventually, if they wish to do so.
If whole_word is true, the client app should do the following:
- Define ‘word constituent characters’ for your app. In the official implementation, it’s
[A-Za-z0-9_]in JavaScript, and[[:word:]]in Ruby. Ruby uses the POSIX character class (Letter | Mark | Decimal_Number | Connector_Punctuation). - If the phrase starts with a word character, and if the previous character before matched range is a word character, its matched range should be treated to not match.
- If the phrase ends with a word character, and if the next character after matched range is a word character, its matched range should be treated to not match.
Please check app/javascript/mastodon/selectors/index.js and app/lib/feed_manager.rb in the Mastodon source code for more details.
Focal points for cropping media thumbnails
Server-side preview images are never cropped, to support a variety of apps and user interfaces. Therefore, the cropping must be done by those apps. To crop intelligently, focal points can be used to ensure a certain section of the image is always within the cropped viewport. See this guide on how focal points are defined. In summary, floating points range from -1.0 to 1.0, left-to-right or bottom-to-top. (0,0) is the center of the image. (0.5, 0.5) would be in the center of the upper-right quadrant. (-0.5, -0.5) would be in the center of the lower-left quadrant. For reference, thumbnails in the Mastodon frontend are most commonly 16:9.
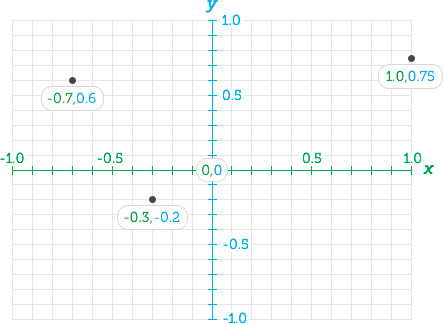
A demonstration of various focal points and their coordinates.